Tanveer Khan Data Scientist @ NextGen Invent | Research Scholar @ Jamia Millia Islamia
Natural Language Processing: Text Generation using FNet transformer
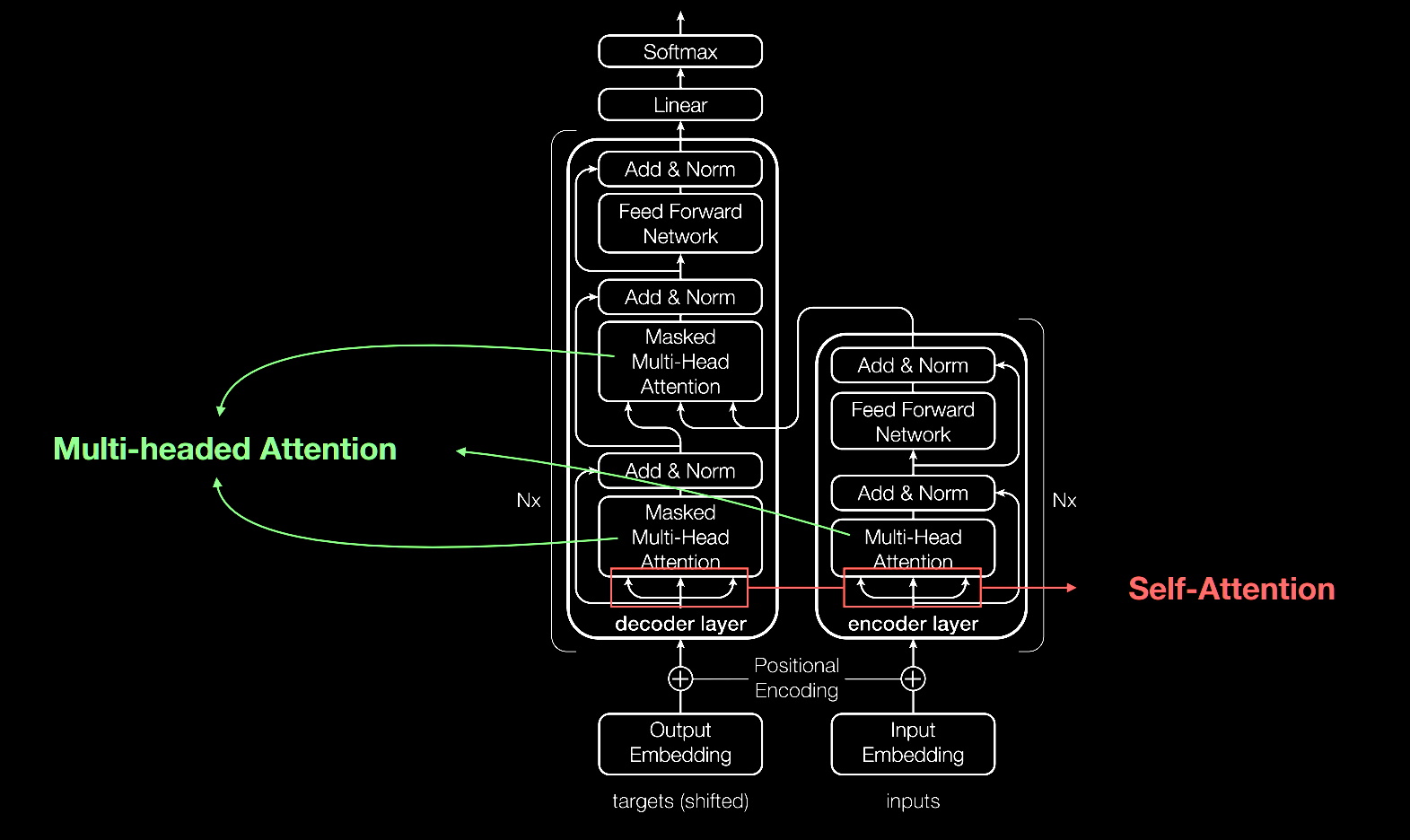
image from web
1. Introduction
Text generation is a popular task in natural language processing (NLP) that involves generating new text that is similar in style and structure to a given input text. FNet is a relatively new neural network architecture that has shown promise in improving the performance of text generation tasks.
The original transformer implementation (Vaswani et al., 2017) was one of the major breakthroughs in Natural Language Processing, giving rise to important architectures such BERT and GPT. However, the drawback of these architectures is that the self-attention mechanism they use is computationally expensive. The FNet architecture proposes to replace this self-attention attention with a leaner mechanism: a Fourier transformation-based linear mixer for input tokens.
FNet is a feedforward neural network that was proposed in 2020 by the researchers at Facebook AI. Unlike traditional neural network architectures that rely on recurrent or convolutional layers, FNet uses self-attention mechanisms similar to those used in the Transformer architecture. To use FNet for text generation, the model is typically trained on a large corpus of text data using a supervised learning approach. During training, the model learns to predict the next word or sequence of words in a given text sequence. Once the model is trained, it can be used to generate new text by sampling from the learned distribution of words or sequences of words.
In this article, we will implement and train FNet model on the Cornell Movie Dialog corpus dataset to show the applicability of FNet in text generation.
2. Dataset
We will use the well-known Cornell Movie Dialog Corpus dataset consisting of conversations between characters from over 600 movies. The dataset was compiled by Cornell University's Department of Computer Science in the early 2000s, and it has since become a popular resource for natural language processing (NLP) and machine learning researchers. The dataset includes over 220,579 conversational exchanges between 10,292 movie character pairs, with each exchange represented as a separate row in a tab-separated values (TSV) file. The dataset can be downloaded from here.
3. Methodology
In this section we will perform Package imports, Data-Loading, Data Pre-processing, Creating FNet Encoder, Creating Decoder, Model Creation & Training , and Perform Inference from the trained model.
Figure below shows the flow chart of the Methodology followed.
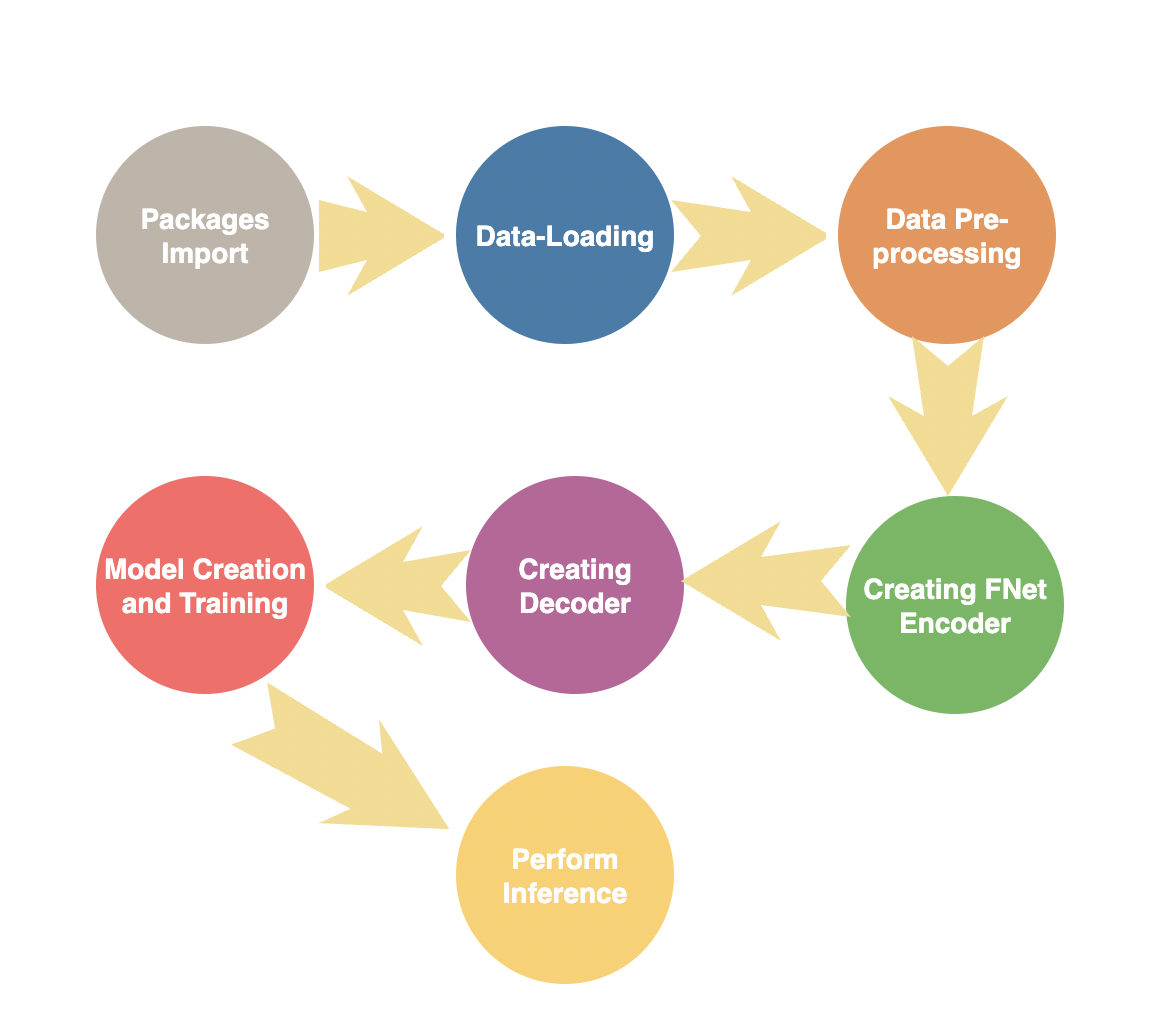
Figure 1. Methodology Flow Chart
3.1 Importing packages
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import os
import re
# Defining hyperparameters
VOCAB_SIZE = 8192
MAX_SAMPLES = 50000
BUFFER_SIZE = 20000
MAX_LENGTH = 40
EMBED_DIM = 256
LATENT_DIM = 512
NUM_HEADS = 8
BATCH_SIZE = 64
3.2 Data Loading
We will be using the Cornell Dialog Corpus. We will parse the movie conversations into questions and answers sets.
path_to_dataset = os.path.join(
os.path.dirname(path_to_zip), "cornell movie-dialogs corpus"
)
path_to_movie_lines = os.path.join(path_to_dataset, "movie_lines.txt")
path_to_movie_conversations = os.path.join(path_to_dataset, "movie_conversations.txt")
def load_conversations():
# Helper function for loading the conversation splits
id2line = {}
with open(path_to_movie_lines, errors="ignore") as file:
lines = file.readlines()
for line in lines:
parts = line.replace("\n", "").split(" +++$+++ ")
id2line[parts[0]] = parts[4]
inputs, outputs = [], []
with open(path_to_movie_conversations, "r") as file:
lines = file.readlines()
for line in lines:
parts = line.replace("\n", "").split(" +++$+++ ")
# get conversation in a list of line ID
conversation = [line[1:-1] for line in parts[3][1:-1].split(", ")]
for i in range(len(conversation) - 1):
inputs.append(id2line[conversation[i]])
outputs.append(id2line[conversation[i + 1]])
if len(inputs) >= MAX_SAMPLES:
return inputs, outputs
return inputs, outputs
questions, answers = load_conversations()
# Splitting training and validation sets
train_dataset = tf.data.Dataset.from_tensor_slices((questions[:40000], answers[:40000]))
val_dataset = tf.data.Dataset.from_tensor_slices((questions[40000:], answers[40000:]))
3.3 Data Pre-Processing
Data processing and tokenization are important steps in natural language processing (NLP) tasks. In NLP, the input text is typically in the form of unstructured data, which needs to be processed and transformed into a format that can be used by machine learning models.
The goal of data processing and tokenization is to extract relevant information from the input text and represent it in a structured form. Data pre-processing involves cleaning, normalizing, and transforming the raw input text data to make it suitable for further analysis. Some common data pre-processing steps include removing stop words, stemming, lemmatization, and removing special characters or punctuation marks.
3.3.1 Preprocessing and Tokenization
def preprocess_text(sentence):
sentence = tf.strings.lower(sentence)
# Adding a space between the punctuation and the last word to allow better tokenization
sentence = tf.strings.regex_replace(sentence, r"([?.!,])", r" \1 ")
# Replacing multiple continuous spaces with a single space
sentence = tf.strings.regex_replace(sentence, r"\s\s+", " ")
# Replacing non english words with spaces
sentence = tf.strings.regex_replace(sentence, r"[^a-z?.!,]+", " ")
sentence = tf.strings.strip(sentence)
sentence = tf.strings.join(["[start]", sentence, "[end]"], separator=" ")
return sentence
vectorizer = layers.TextVectorization(
VOCAB_SIZE,
standardize=preprocess_text,
output_mode="int",
output_sequence_length=MAX_LENGTH,
)
# We will adapt the vectorizer to both the questions and answers
# This dataset is batched to parallelize and speed up the process
vectorizer.adapt(tf.data.Dataset.from_tensor_slices((questions + answers)).batch(128))
3.3.2 Tokenizing and padding sentences using TextVectorization
Tokenization is the process of breaking down the input text into individual words or tokens. This is typically done by splitting the input text on whitespace or punctuation marks.
In addition to splitting the text into individual tokens, tokenization may also involve lowercasing the tokens and removing any stop words. Tokenization is a critical step in many NLP tasks, including text classification, sentiment analysis, and machine translation. Once the input text has been tokenized, the resulting tokens can be further processed and analyzed using various NLP techniques such as vectorization, named entity recognition, or part-of-speech tagging.
def vectorize_text(inputs, outputs):
inputs, outputs = vectorizer(inputs), vectorizer(outputs)
# One extra padding token to the right to match the output shape
outputs = tf.pad(outputs, [[0, 1]])
return (
{"encoder_inputs": inputs, "decoder_inputs": outputs[:-1]},
{"outputs": outputs[1:]},
)
train_dataset = train_dataset.map(vectorize_text, num_parallel_calls=tf.data.AUTOTUNE)
val_dataset = val_dataset.map(vectorize_text, num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = (
train_dataset.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.prefetch(tf.data.AUTOTUNE)
)
val_dataset = val_dataset.cache().batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
3.4 Creating FNet Encoder
The FNet paper proposes a replacement for the standard attention mechanism used by the Transformer architecture (Vaswani et al., 2017).
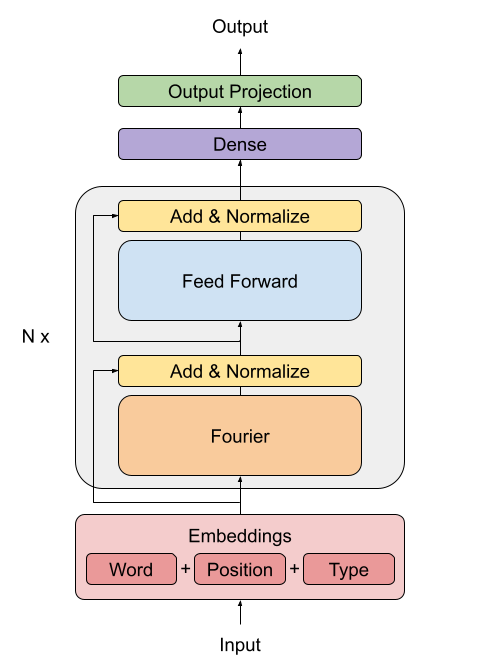
Figure 2. FNet model architecture
The outputs of the FFT layer are complex numbers. To avoid dealing with complex layers, only the real part (the magnitude) is extracted.
The dense layers that follow the Fourier transformation act as convolutions applied on the frequency domain.
class FNetEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.dense_proj = keras.Sequential(
[
layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs):
# Casting the inputs to complex64
inp_complex = tf.cast(inputs, tf.complex64)
# Projecting the inputs to the frequency domain using FFT2D and
# extracting the real part of the output
fft = tf.math.real(tf.signal.fft2d(inp_complex))
proj_input = self.layernorm_1(inputs + fft)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
3.5 Creating FNet Decoder
The decoder architecture remains the same as the one proposed by (Vaswani et al., 2017) in the original transformer architecture, consisting of an embedding, positional encoding, two masked multihead attention layers and finally the dense output layers.
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, vocab_size, embed_dim, **kwargs):
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding(
input_dim=vocab_size, output_dim=embed_dim
)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=embed_dim
)
self.sequence_length = sequence_length
self.vocab_size = vocab_size
self.embed_dim = embed_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
def compute_mask(self, inputs, mask=None):
return tf.math.not_equal(inputs, 0)
class FNetDecoder(layers.Layer):
def __init__(self, embed_dim, latent_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.latent_dim = latent_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.dense_proj = keras.Sequential(
[
layers.Dense(latent_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True
def call(self, inputs, encoder_outputs, mask=None):
causal_mask = self.get_causal_attention_mask(inputs)
if mask is not None:
padding_mask = tf.cast(mask[:, tf.newaxis, :], dtype="int32")
padding_mask = tf.minimum(padding_mask, causal_mask)
attention_output_1 = self.attention_1(
query=inputs, value=inputs, key=inputs, attention_mask=causal_mask
)
out_1 = self.layernorm_1(inputs + attention_output_1)
attention_output_2 = self.attention_2(
query=out_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
)
out_2 = self.layernorm_2(out_1 + attention_output_2)
proj_output = self.dense_proj(out_2)
return self.layernorm_3(out_2 + proj_output)
def get_causal_attention_mask(self, inputs):
input_shape = tf.shape(inputs)
batch_size, sequence_length = input_shape[0], input_shape[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
mult = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)],
axis=0,
)
return tf.tile(mask, mult)
3.6 Model Creation and Training
def create_model():
encoder_inputs = keras.Input(shape=(None,), dtype="int32", name="encoder_inputs")
x = PositionalEmbedding(MAX_LENGTH, VOCAB_SIZE, EMBED_DIM)(encoder_inputs)
encoder_outputs = FNetEncoder(EMBED_DIM, LATENT_DIM)(x)
encoder = keras.Model(encoder_inputs, encoder_outputs)
decoder_inputs = keras.Input(shape=(None,), dtype="int32", name="decoder_inputs")
encoded_seq_inputs = keras.Input(
shape=(None, EMBED_DIM), name="decoder_state_inputs"
)
x = PositionalEmbedding(MAX_LENGTH, VOCAB_SIZE, EMBED_DIM)(decoder_inputs)
x = FNetDecoder(EMBED_DIM, LATENT_DIM, NUM_HEADS)(x, encoded_seq_inputs)
x = layers.Dropout(0.5)(x)
decoder_outputs = layers.Dense(VOCAB_SIZE, activation="softmax")(x)
decoder = keras.Model(
[decoder_inputs, encoded_seq_inputs], decoder_outputs, name="outputs"
)
decoder_outputs = decoder([decoder_inputs, encoder_outputs])
fnet = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs, name="fnet")
return fnet
fnet = create_model()
fnet.compile("adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
Here, the epochs parameter is set to a single epoch, but in practice the model will take around 20-30 epochs of training to start outputting comprehensible sentences. Although accuracy is not a good measure for this task, we will use it just to get a hint of the improvement of the network.
fnet.fit(train_dataset, epochs=1, validation_data=val_dataset)
3.7 Perform Inference
VOCAB = vectorizer.get_vocabulary()
def decode_sentence(input_sentence):
# Mapping the input sentence to tokens and adding start and end tokens
tokenized_input_sentence = vectorizer(
tf.constant("[start] " + preprocess_text(input_sentence) + " [end]")
)
# Initializing the initial sentence consisting of only the start token.
tokenized_target_sentence = tf.expand_dims(VOCAB.index("[start]"), 0)
decoded_sentence = ""
for i in range(MAX_LENGTH):
# Get the predictions
predictions = fnet.predict(
{
"encoder_inputs": tf.expand_dims(tokenized_input_sentence, 0),
"decoder_inputs": tf.expand_dims(
tf.pad(
tokenized_target_sentence,
[[0, MAX_LENGTH - tf.shape(tokenized_target_sentence)[0]]],
),
0,
),
}
)
# Calculating the token with maximum probability and getting the corresponding word
sampled_token_index = tf.argmax(predictions[0, i, :])
sampled_token = VOCAB[sampled_token_index.numpy()]
# If sampled token is the end token then stop generating and return the sentence
if tf.equal(sampled_token_index, VOCAB.index("[end]")):
break
decoded_sentence += sampled_token + " "
tokenized_target_sentence = tf.concat(
[tokenized_target_sentence, [sampled_token_index]], 0
)
return decoded_sentence
decode_sentence("Where have you been all this time?")
OUTPUT: Are you asking me?
4. Conclusion
In this article we created and trained FNet model for text generation. Our experiment demonstrated that FNet-based models can generate high-quality text with improved efficiency compared to traditional transformer-based models.
The self-attention mechanism in FNet utilizes a different approach to process sequential data, which reduces the computational overhead and makes it suitable for handling long sequences. This article suggests that FNet can be a viable alternative to traditional transformer-based models for text generation tasks.
References
- Lee-Thorp, J., Ainslie, J., Eckstein, I., & Ontanon, S. (2021). Fnet: Mixing tokens with fourier transforms. arXiv preprint arXiv:2105.03824.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.