Tanveer Khan Data Scientist @ NextGen Invent | Research Scholar @ Jamia Millia Islamia
Superstore sales data analysis using Big Data Hadoop framework
Big Data Analytics refers to the strategy of analyzing large volumes of data, or big data. This big data is gathered from a wide variety of sources, including social networks, videos, digital images, log files, sensor data, and sales transaction records, etc. The aim is to analyze all this data to discover patterns, findings, and trends that will help the concerned stakeholders to take informed decisions.
Objectives
The general and specific objectives are being discussed in this section.
General objective:
The main objective here is to use big data hadoop framework for analyzing superstore sales data and to design a Graphical user interface (GUI) for the same.
Specific objectives:
- To design a user interface which will interact with HDFS a, distributed data warehouse using gateway node.
- To produce MapReduce jobs and HIVE queries for the analysis of the superstore data file.
- To install the Hadoop v2.7.5 in standalone mode together with all its frameworks and applications for the analysis purpose.
Dataset
Superstore Sales - This dataset has transactions records of US customers from years 2014-2018 for an E-commerce platform that allows people to buy products from books, toys, clothes, and shoes to food, furniture, and other household items.
Motivation
Our motivation lies in exploring superstore dataset for finding answers to these questions.
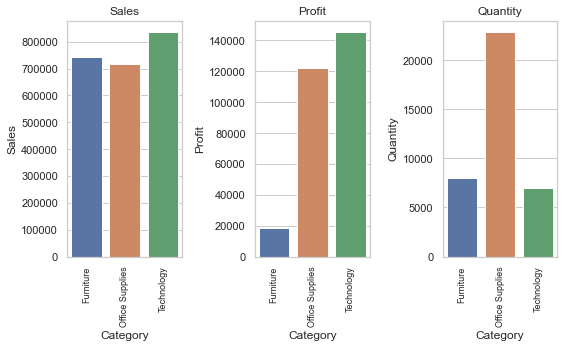
- How much profit is gained for each product.?
- People from city/state shop the most?
- Average total sales purchase price per cutomer.?
- Finding category wise total sales price.?
- Customer total purchase price.?
- Total Profit attained by an individual customer.?
- State region wise total sales price.?
- Total number of transactions by an individual customer.?
- Quantity based analysis.?
Requirements
Hardware requirements:
- System with i3 processor or later
- System with Minimum 4GB RAM and minimum 20GB Hard Drive.
- System having Virtualization Technology (in case if using windows).
Software requirements:
- Operating System:Windows 7 or later or Linux v12.04 or later.
- VMware-workstation-full-14.1
- Cloudera-quickstart-vm-4.7.0-0-vmware
- Hadoop-2.9.0.tar, apache-hive-1.2.2-bin.tar.gz, sqoop-1.4.7.bin_hadoop- 2.6.0.tar.gz, pig-0.16.0-src.tar.gz
- Java development toolkit: jdk-8u152-linux-x64.tar.
- netbeans-8.2-windows for design and development purpose.
Methodology
The proposed methodology for deisgn and development of Graphical user interface (GUI) and writing MapReduce jobs and HIVE queries for analysis pupose have been discussed here.
Building a graphical user interface (GUI)
For this purpose Netbeans software was used for designing a GUI. The figures below shows the flow chart and data flow diagram of the build system.
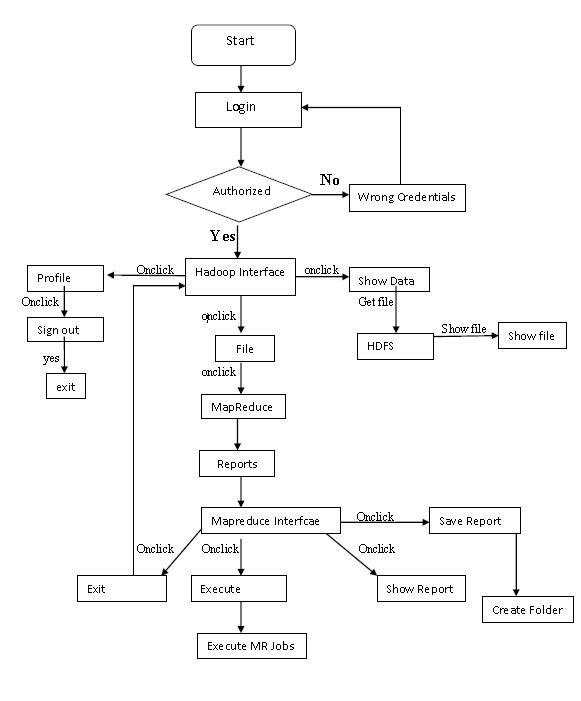
Flow chart of the proposed system.
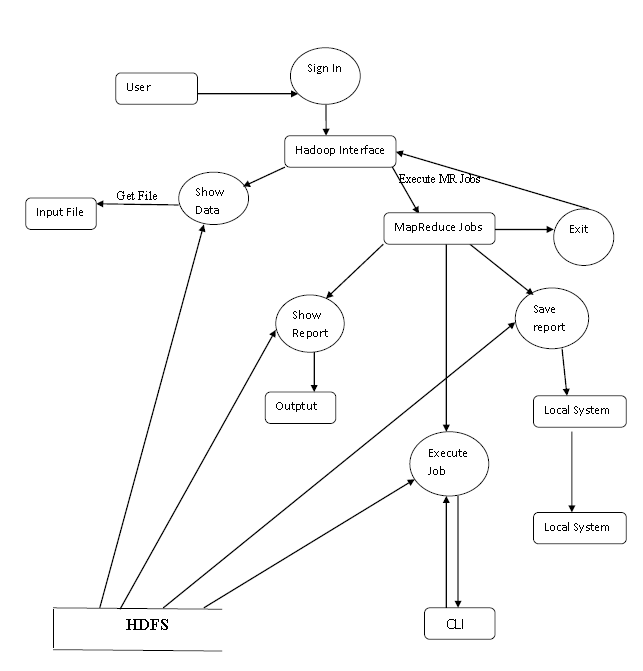
Data flow Diagram of the proposed system.
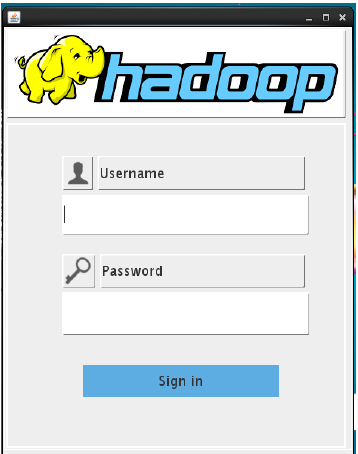
Figures below shows the developed GUI for the proposed system. For the purpose of analyzing superstore dataset the developed GUI has screens for authorization purpose, Execution of MapReduce jobs, generating reports, and saving the reports to the local system.
Login screen design for authorization purpose.
Screen design for generating MapReduce jobs.
Screen design for for generating reports.
The soucre code for the design and development of the proposed sytem system can be found here.
Single Node Hadoop Installation on Linux v16.04:
Installing Java
:~$ cd ~
# Update the source list
~$ sudo apt-get update
# The OpenJDK project is the default version of Java
# that is provided from a supported Ubuntu repository.
:~$ sudo apt-get install default-jdk
:~$ java -version
java version "1.7.0_65"
OpenJDK Runtime Environment (IcedTea 2.5.3) (7u71-2.5.3-0ubuntu0.14.04.1)
OpenJDK 64-Bit Server VM (build 24.65-b04, mixed mode)
Adding a dedicated Hadoop user
:~$ sudo addgroup hadoop
Adding group `hadoop' (GID 1002) ... Done.
:~$ sudo adduser --ingroup hadoop hduser
Adding user `hduser' ...
Adding new user `hduser' (1001) with group `hadoop' ...
Creating home directory `/home/hduser' ...
Copying files from `/etc/skel' ...
Enter new UNIX password
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for hduser
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] Y
Install Hadoop
:~$ wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
:~$ tar xvzf hadoop-2.6.0.tar.gz
:/home/hduser$ sudo su hduser
:~/hadoop-2.6.0$ sudo mv * /usr/local/hadoop
:~/hadoop-2.6.0$ sudo chown -R hduser:hadoop /usr/local/hadoop
The following files will have to be modified to complete the Hadoop setup:
~/.bashrc
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
/usr/local/hadoop/etc/hadoop/core-site.xml
/usr/local/hadoop/etc/hadoop/mapred-site.xml.template
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
1. ~/.bashrc:
Before editing the .bashrc file in our home directory, we need to find the path where Java has been
installed to set the JAVA_HOME environment variable using the following command.
hduser@laptop update-alternatives --config java
There is only one alternative in link group java (providing /usr/bin/java):/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
Nothing to configure.
# Now we can append the following to the end of ~/.bashrc:
hduser@laptop:~$ vi ~/.bashrc
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
hduser@laptop:~$ source ~/.bashrc
2. Editing the /usr/local/hadoop/etc/hadoop/hadoop-env.sh.
We need to set JAVA_HOME by modifying hadoop-env.sh file.
hduser@laptop:~$ vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
3. Editing the/usr/local/hadoop/etc/hadoop/core-site.xml:
The /usr/local/hadoop/etc/hadoop/core-site.xml file contains configuration properties that Hadoop uses when starting up. This file can be used to override the default settings that Hadoop starts with.
Open the file and enter the following in between the
hduser@laptop:~$ vi /usr/local/hadoop/etc/hadoop/core-site.xml
hadoop.tmp.dir
/app/hadoop/tmp
A base for other temporary directories.
4. Editing the mapred-site.xml.template file.
By default the /usr/local/hadoop/etc/hadoop/ folder contains /usr/local/hadoop/etc/hadoop/mapred-site.xml.template. The mapred-site.xml file is used to specify which framework is being used for MapReduce. We need to enter the following content in between the
mapred.job.tracker
localhost:54311
The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
5. Editing the /usr/local/hadoop/etc/hadoop/hdfs-site.xml.
The /usr/local/hadoop/etc/hadoop/hdfs-site.xml file needs to be configured for each host in the cluster that is being used. It is used to specify the directories which will be used as the namenode and the datanode on that host. Before editing this file, we need to create two directories which will contain the namenode and the datanode for this Hadoop installation. Open the file and enter the following content in between the
hduser@laptop:~$ vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop_store/hdfs/namenode
dfs.datanode.data.dir
file:/usr/local/hadoop_store/hdfs/datanode
Format the New Hadoop Filesystem. Now, the Hadoop file system needs to be formatted so that we can start to use it. The format command should be issued with write permission since it creates current directory under /usr/local/hadoop_store/hdfs/namenode folder. After this we are good to go..!!!
Conclusion
The Proposed system will provide us with the Graphical User interface (GUI) for performing the execution of MapReduce jobs efficiently and in an easy way by analyzing large dataset on Big Data Hadoop single node cluster. Additionally, proposed system will act as baseline for other datasets as we can modify it with the reports we want to execute by producing MapReduce Jobs for the same.
References
- Saldhi, A., Yadav, D., Saksena, D., Goel, A., Saldhi, A., & Indu, S. (2014, December). Big data analysis using Hadoop cluster. In 2014 IEEE International Conference on Computational Intelligence and Computing Research (pp. 1-6). IEEE.
- Nayak, B. (2020). Hadoop Internals and Big Data Evidence. In Big Data Analytics and Computing for Digital Forensic Investigations (pp. 65-86). CRC Press.
- Kumar, N. (2021). Big Data Using Hadoop and Hive. Stylus Publishing, LLC.