Tanveer Khan Data Scientist @ NextGen Invent | Research Scholar @ Jamia Millia Islamia
Building an on-device Recommendation system
This article provides an adaptive framework to train and serve on-device recommendation system model. This approach personalizes recommendations by leveraging on-device data, and protects user privacy without having user data leave device.
Image from web
Introduction
Personalized recommendations play a significant role in digital life nowadays. With more and more user actions being moved to edge devices, supporting recommenders on-device becomes an important direction. Compared with conventional pure server-based recommenders, the on-device solution has unique advantages, such as protecting users’ privacy, providing fast reaction to on-device user actions, leveraging lightweight TensorFlow Lite inference, and bypassing network dependency.
Recommendation system model
A recommendation system typically predicts users’ future activities, based on users’ previous activities. Our framework supports models using context information to do the prediction, which can be described in the following architecture:
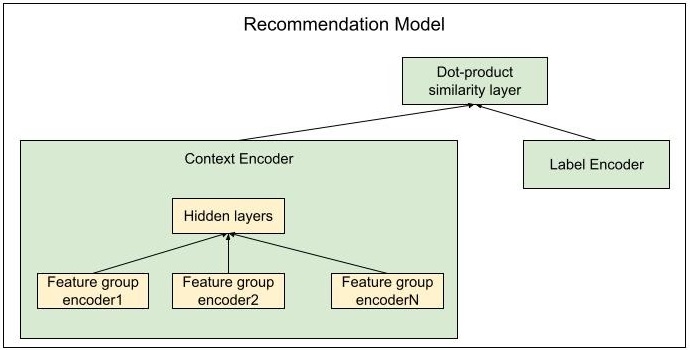
Figure 1. Adaptable recommendation model
We leverage a dual-encoder model architecture, with context-encoder to encode sequential user history and label-encoder to encode predicted recommendation candidate. Similarity between context and label encodings is used to represent the likeliness predicted candidate meets user’s needs.
Three different sequential user history encoding techniques are explored in this article:
Bag of words encoder (BOW): averaging user activities’ embedding’s without considering context order.
Convolutional neural-network encoder (CNN): applying multiple layers of convolutional neural-network to generate context encoding.
Recurrent neural-network encoder (RNN): applying recurrent neural network (LSTM in this example) to understand context sequence.
In terms of user sequence modeling, there are two approaches in general:
Id-based: putting all recommendation candidates in an embedding space to understand similarities of items. The embedding’s are keyed with item Ids in the item vocabulary. Hence we call it id-based approach.
Feature-based: use more features of user activities, not only the item ids. For instance, movie genre and movie rating for movie recommendation. The model will understand the features and learns the way to understand user.
This framework code base supports both id-based and feature-based recommendation models, with a configurable way.
Data Adaptivity
The proposed framework can support model training or customization with various kinds of data, for which we can configure the input data and encoder architecture.
With the input configuration, we can specify the input features’ information, such as data type, shape, vocab, embedding dimension. We can also freely group features in a feature group to encode together, for instance movie_id and movie rating in above diagram. We support 3 feature types INT/STRING/FLOAT, for string and integer categorical features we will map them in embedding spaces, for float feature we will concatenate them together with other features’ embedding’s.
Methodology
To demonstrate the adaptive framework, we will train an on-device movie recommendation model with publicly available MovieLens dataset using multiple features. The MovieLens 1M dataset contains ratings from 6039 users across 3951 movies, with each user rating only a small subset of movies.
1. Environment preparation
git clone https://github.com/tensorflow/examples
cd examples/lite/examples/recommendation/ml/
pip install -r requirements.txt
2. Training Data Preparation
Preparing our training data reference to the MovieLens example generation file. Would like to note that TensorFlow Lite input features are expected to be FixedLenFeature, please pad or truncate your features, and set up feature lengths in input configuration.
2.1 Examples Generation
The examples generation process performs the following steps:
Download MovieLens dataset
Groups movie rating records by user, and orders per-user movie rating records by timestamp.
Generates TensorFlow examples with features:
1) context_movie_id: time-ordered sequential movie IDs
2) context_movie_rating: time-ordered sequential rating numbers
3) context_movie_genre: time-ordered sequential movie genres
4) context_movie_year: time-ordered sequential movie years.
5) label_movie_id: the next movie ID user rated.
There’s case that one user activity will have multiple values for a single feature. For example, the movie genre feature in movielens dataset, each movie can have multiple genres. For this case, we will concatenate all movies’ genres for the activity sequence. Let’s look at one example, if the user activity sequence is:
Star Wars: Episode IV - A New Hope (1977), Genres: Action|Adventure|Fantasy
Terminator 2: Judgment Day (1991), Genres: Action|Sci-Fi|Thriller
Jurassic Park (1993), Genres: Action|Adventure|Sci-Fi
The context_movie_genre feature will be:
"Action, Adventure, Fantasy, Action, Sci-Fi, Thriller, Action, Adventure, Sci-Fi"
Since TFLite input tensors should be fixed length, so padding features to fixed length is a desirable option.
Since TFLite input tensors should be fixed length, so padding features to fixed length is a desirable option.
2.2 Vocabularies Generation
For String and Integer type features, we will create an embedding space for each of them, for which vocabularies will be needed. This framework supports txt file based vocabulary setup, for which you can push vocab item line-by-line in a txt file. And in the training input pipeline vocabularies will be formed as:
tf.lookup.StaticVocabularyTable(
tf.lookup.TextFileInitializer(
vocab_path,
key_dtype=key_type,
key_index=tf.lookup.TextFileIndex.WHOLE_LINE,
value_dtype=tf.int64,
value_index=tf.lookup.TextFileIndex.LINE_NUMBER,
delimiter='\t'),
num_oov_buckets)
And vocab_path is the path to the generated vocabulary txt file.The data/example_generation_movielens.py script, generates vocabularies with "--build_vocabs" set as true.
2.3 Data preparation
Training examples and vocabulary can be generated by compiling script below.
Note: If you would like to use your own data, please adapt the data processing script for your specific case.
!python -m data.example_generation_movielens \
--data_dir=data/raw \
--output_dir=data/examples \
--min_timeline_length=3 \
--max_context_length=10 \
--max_context_movie_genre_length=32 \
--min_rating=2 \
--train_data_fraction=0.9 \
--build_vocabs=True
Raw movielens ratings.dat data is in the following format: UserID::MovieID::Rating::Timestamp
UserIDs range between 1 and 6040
MovieIDs range between 1 and 3952
Ratings are made on a 5-star scale (whole-star ratings only)
Timestamp is represented in seconds since the epoch as returned by time(2)
Each user has at least 20 ratings
3. Model Input Configurationn
Once data prepared, we will set up input configuration for MovieLens recommendation model. Trainer code will prepare tf datasets and set up model according to input configuration.
Feature: name, data type, feature length, vocab name, vocab size, embedding dimension.
Feature group: features to encode together, encoder type.
Global feature groups: global features, e.g. user age, profession etc.
Activity feature groups: features to represent activities.
Label feature: the feature used as label.
Both input data processing and model architecture setup will be based on the input configuration. We can check for an example input config with command below:
!cat configs/sample_input_config.pbtxt
OUTPUT:
activity_feature_groups {
features {
feature_name: "context_movie_id"
feature_type: INT
vocab_size: 3953
embedding_dim: 8
feature_length: 10
}
features {
feature_name: "context_movie_rating"
feature_type: FLOAT
feature_length: 10
}
encoder_type: CNN
}
activity_feature_groups {
features {
feature_name: "context_movie_genre"
feature_type: STRING
vocab_name: "movie_genre_vocab.txt"
vocab_size: 19
embedding_dim: 4
feature_length: 32
}
encoder_type: CNN
}
label_feature {
feature_name: "label_movie_id"
feature_type: INT
vocab_size: 3953
embedding_dim: 8
feature_length: 1
}
4. Train model
The model trainer will construct the recommendation model based on the input config, with a simple interface.
The training launcher script uses TensorFlow keras compile/fit APIs and performs the following steps to kick off training and evaluation process:
Set up both train and eval dataset input function.
Construct keras model according to provided configs, please refer to sample.config file in the source code to
config your model architecture, such as embedding dimension, convolutional neural network params, LSTM units etc.
Setup loss function. In this code base, we leverage customized batch softmax loss function.
Setup optimizer, with flag specified learning rate and gradient clip if needed.
Setup evaluation metrics, we provided recall@k metrics by default.
Compile model with loss function, optimizer and defined metrics.
Setup callbacks for tensorboard and checkpoint manager.
Run model.fit with compiled model, where you could specify number of epochs to train, number of train steps in each epoch and number of eval steps in each epoch.
Start training by executing below mentioned command:
!python -m model.recommendation_model_launcher \
--training_data_filepattern "data/examples/train_movielens_1m.tfrecord" \
--testing_data_filepattern "data/examples/test_movielens_1m.tfrecord" \
--model_dir "model/model_dir" \
--export_dir "model/model_dir/export_m1" \
--vocab_dir "data/examples" \
--input_config_file "configs/sample_input_config.pbtxt" \
--batch_size 32 \
--learning_rate 0.01 \
--steps_per_epoch 2 \
--num_epochs 2 \
--num_eval_steps 2 \
--run_mode "train_and_eval" \
--gradient_clip_norm 1.0 \
--num_predictions 10 \
--hidden_layer_dims "32,32" \
--eval_top_k "1,5" \
--conv_num_filter_ratios "2,4" \
--conv_kernel_size 4 \
--lstm_num_units 16
Inside the recommendation model, core components are packaged up to keras layers (context_encoder.py, label_encoder.py and dotproduct_similarity.py), each of which could be utilized by itself. The following diagram illustrates the code structure:
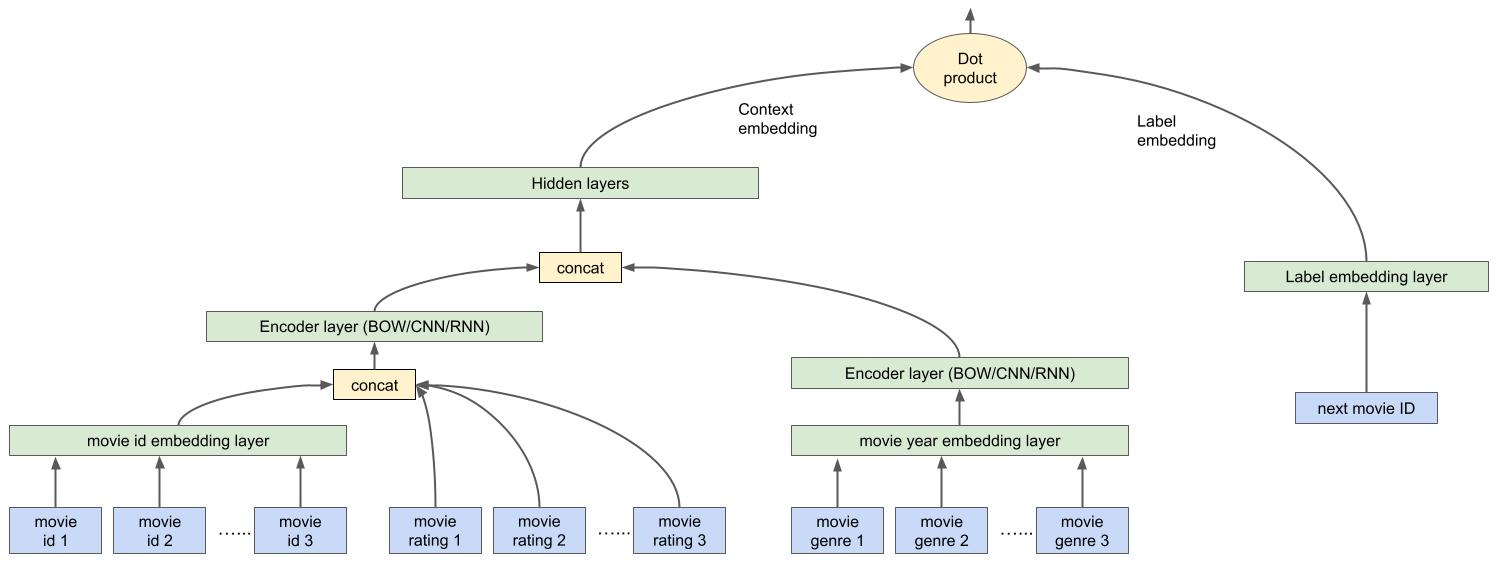
Figure 2. Recommendation system model architecture.
5. Model inference
We can verify our model’s performance by running inference with test examples.
import os
import tensorflow as tf
# Use [0, 1, ... 9] as example input to represent 10 movies that user interacted with.
context = tf.range(10)
# Path to exported TensorFlow Lite model.
tflite_model_path = 'model/model_dir/export/export_m2/model.tflite' #@param {type:"string"}
# Create TFLite interpreter.
interpreter = tf.lite.Interpreter(tflite_model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print('Display inputs and outputs:')
print(input_details)
print(output_details)
# Find indices.
names = [
'serving_default_context_movie_id:0',
'serving_default_context_movie_genre:0',
'serving_default_context_movie_rating:0',
]
indices = {i['name']: i['index'] for i in input_details}
# Fake inputs for illustration. Please change to the real data.
# Use [0, 1, ... 9] to represent 10 movies that user interacted with.
ids = tf.range(10)
interpreter.set_tensor(indices[names[0]], ids)
# Use [0, 1, ..., 31] to represent 32 movie genres.
genres = tf.range(32)
interpreter.set_tensor(indices[names[1]], genres)
# Use [1.0, 1.0, ..., 1.0] to represent 10 movie ratings.
ratings = tf.ones(10)
interpreter.set_tensor(indices[names[2]], ratings)
# Run inference.
interpreter.invoke()
# Get outputs.
top_prediction_ids = interpreter.get_tensor(output_details[0]['index'])
top_prediction_scores = interpreter.get_tensor(output_details[1]['index'])
print('Predicted results:')
print('Top ids: {}'.format(top_prediction_ids))
print('Top scores: {}'.format(top_prediction_scores))
###############################
OUTPUT:
Predicted results:
Top ids: [0.53385556 0.53278863 0.53226066 0.5320673 0.53171206 0.53167486 0.53085494 0.53042835 0.5304034 0.5290739 ]
Top scores: [3272 531 2446 96 3680 2726 3176 1497 1791 903]
Conclusion
In this article, we build an on-device recommendation system with publicly available MovieLens dataset, this proposed framework is adaptable to other datasets and can be configured for building other recommendation system’s. Our framework provides a protobuf interface, through which feature groups, types and other information can be configured to build recommendation models accordingly.